· 3 min read
Hey Neo, can you help me to classify the intents of Croatian utterances?
Intent Classification Models - Cross-lingual Transfer Learning
Recent studies of intent classification models on task-oriented dialogs are mainly focused on monolingual settings – train on annotated English data and evaluate on annotated English data. However, if we want to work on a task-oriented dialog system with low-resource languages (e.g., Croatian, Polish), or on multilingual cases (i.e., a single model can work with 3+ languages), how can we efficiently train the model without the abundant annotated data for resource-lean target languages.
An intuitive way will be the Cross-lingual Transfer Learning (CLTL) approach, which is a viable method to building NLP models for low-resource target languages by leveraging labeled data from other (source) languages. Cross-lingual transfer refers to transfer learning using data and models available in one language that has sufficient resources (e.g., English) to solve tasks in another, commonly more low-resource, language (e.g., Croatian). Language transfer requires the representation of texts from both the source and target language in a shared cross-lingual space. Recent years language transfer methods based on continuous representation spaces have proliferated. The previous state-of-the-art, cross-lingual word embeddings (CLWEs) [1] and sentence embeddings [2], have recently been superseded by massively multilingual transformers (MMTs) pretrained with language model (LM) objectives (e.g., mBERT [3], XLM-R [4]). Since MMTs are pretrained on large multilingual (i.e., 100+ languages) text corpora, it’s rich for its multilingual capabilities of cross-lingual transfer setup (e.g., from English to Croatian).
We can perform the cross-lingual transfer either via zero-shot or few-shot learning to train with none or few target language annotated data. Or focusing on the multilingual transfer setting leveraging training data in multiple source languages to further improve performance in the target language. As illustrated in the following figure, we can easily train an intent classification model in English, since it contains rich annotated data, and PLMs (e.g., bert-base-cased in English). However, so far there’s no PLM in Croatian. Therefore, we can utilize multilingual pretrained transformers (e.g., mBERT, XLM-R) to further conduct cross-lingual transfer via zero-shot or few-shot or multilingual transfer setup leveraged training data in multiple source languages.
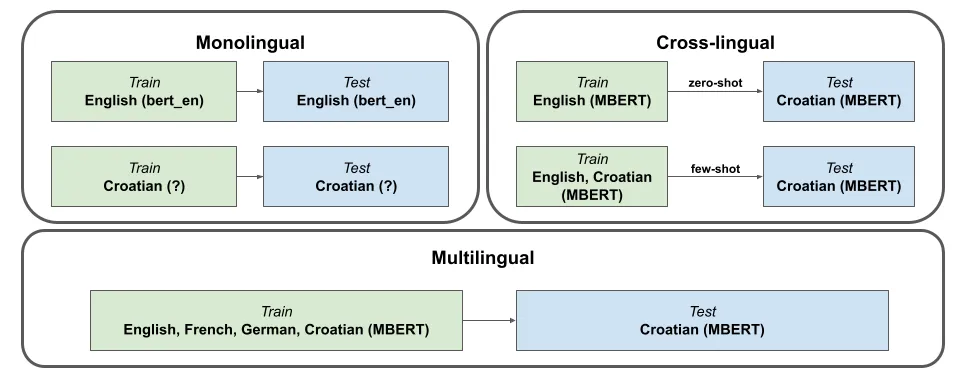 Overview of monolingual, cross-lingual and multilingual setup of training model in Croatian
Overview of monolingual, cross-lingual and multilingual setup of training model in Croatian
Pretrained Language Models
The collection of pretrained language models (PLMs) can be easily obtained from Huggingface [5]:
- Monolingual: bert-base-cased, bert-base-german-cased
- Bilingual: Helsinki-NLP/opus-mt-en-de,
- Multilingual: bert-base-multilingual-cased, xlm-roberta-base
Further details can be found from their elaborated documentation [6] including the usage of models, detailed implementation of various downstream tasks, and the flexibility of efficient training ways.
[1] Goran Glavaš, Robert Litschko, Sebastian Ruder, and Ivan Vulić. 2019. How to (properly) evaluate cross-lingual word embeddings: On strong baselines, comparative analyses, and some misconceptions. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 710–721.
[2] Mikel Artetxe and Holger Schwenk. 2019. Massively multilingual sentence embeddings for zeroshot cross-lingual transfer and beyond. Transactions of the Association for Computational Linguistics, 7:597–610.
[3] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186.
[4] Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettle-moyer, and Veselin Stoyanov. 2020. Unsupervised cross-lingual representation learning at scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8440–8451, Online.
[5] HuggingFace models: https://huggingface.co/models
[6] HuggingFace docs: https://huggingface.co/docs