· 5 min read
Hey Neo, wie viele Sprachen kennst Du? - Multilinguale Domänen für Chat- und Voicebots
Anwendungsfälle für das Multi2ConvAI Forschungsprojekt - Corona-Chatbot, Sprachassistent für Qualitätssicherung und Assistent für die Last-Mile-Delivery
Sprachassistenten und Chatbots bieten einen entscheidenden Vorteil in der Anwendung: Sie sind für Anwender sehr einfach nutzbar, da sie sich dem Anwender anpassen und „seine” Sprache verstehen – zumindest ist dies das Ziel. In der Realität aber muss man sich häufig doch konkrete Befehle merken und die Anfragen so formulieren, dass sie vom Chatbot verstanden werden. Aber warum ist das so? Sollte eine „Künstliche Intelligenz” nicht in der Lage sein, natürliche Sprache zu verstehen?
Das Problem liegt hierbei nicht primär in der Technologie, sondern vor allem auch in der Erstellung und Pflege der Trainingsdaten für das Verständnis von natürlicher Sprache. Häufig erfolgt dies über ein Tool im Hintergrund. Dabei wird über eine manuelle Klassifikation bisheriger Dialoge und über die Kuratierung von Antworten das Sprachmodell trainiert: Inhalte müssen gepflegt werden und die Datenmodelle auf Basis von realen Interaktionsdaten sukzessiv verbessert werden. Dieser Prozess kann schon für eine Sprache aufwändig sein – wie ist das erst, wenn wir 5, 20 oder 100 Sprachen unterstützen möchten?
Ziel des Forschungsprojekts
Im Rahmen des Multi2ConvAI Forschungsprojektes wird genau diese Problemstellung thematisiert: In realen Anwendungsfällen kommt es oft vor, dass Modelle auf kleinen spezifischen Korpora oder – in Extremfällen – ohne verfügbare Dialoge in einer Zielsprache oder -domäne trainiert werden müssen. Das Forschungsvorhaben evaluiert daher Methoden zum Transfer von Conversational-AI-Modellen zu verschiedenen Domänen und Sprachen.
Wahl der Anwendungsfälle
Besonders wichtig ist dem Forschungsvorhaben dabei, einen Praxisbezug herzustellen und nicht von einem Wunschbild auszugehen: In der Realität verfügt man im ersten Schritt häufig nur wenige oder sogar keine Trainingsdaten; diese müssen zumeist iterativ mit Anwendern aufgebaut werden. Daher fokussiert sich das Forschungsvorhaben auf Anwendungsfälle, in denen Trainingsdaten nur begrenzt verfügbar sind. Außerdem ist dem Forschungsvorhaben wichtig, anhand verschiedener Anwendungsfälle auch unterschiedliche Komplexitäten in Dialogen und Daten abzubilden und Use-Cases zu identifizieren, bei denen die Multilingualität eine entscheidende Rolle spielt: Ein FAQ-Chatbot verhält sich zum Beispiel anders, als ein Sprachassistent in einem Qualitätsprozess an verschiedenen Standorten.
Corona-Chatbot: Wichtige Fragen schnell beantwortet
Klassische Chatbots sind vor allem bei hohem Volumen und einfacher Zugänglichkeit im Einsatz. Die Corona-Pandemie hat viele Institutionen und Einrichtungen vor massive Herausforderungen gestellt: Wie kann man ein hohes Anfrage-Volumen in kurzer Zeit akkurat bearbeiten?
Die Neohelden haben in dieser Zeit mit einigen Kunden in wenigen Tagen Chatbots entwickelt, die genau diese Aufgabe übernommen haben. So kann einerseits eine hohe Verfügbarkeit und Skalierbarkeit in der Bearbeitung von Anfragen gewährleistet werden, andererseits können sich die „menschlichen Kollegen” des Assistenten so auf komplexe und individuelle Fälle fokussieren. Neben dem Automatisierungspotential erhöhen Chatbots auch die Barrierefreiheit: Sie sind auf dem Smartphone und im Web über Chat oder sogar über Sprachsteuerung verfügbar.
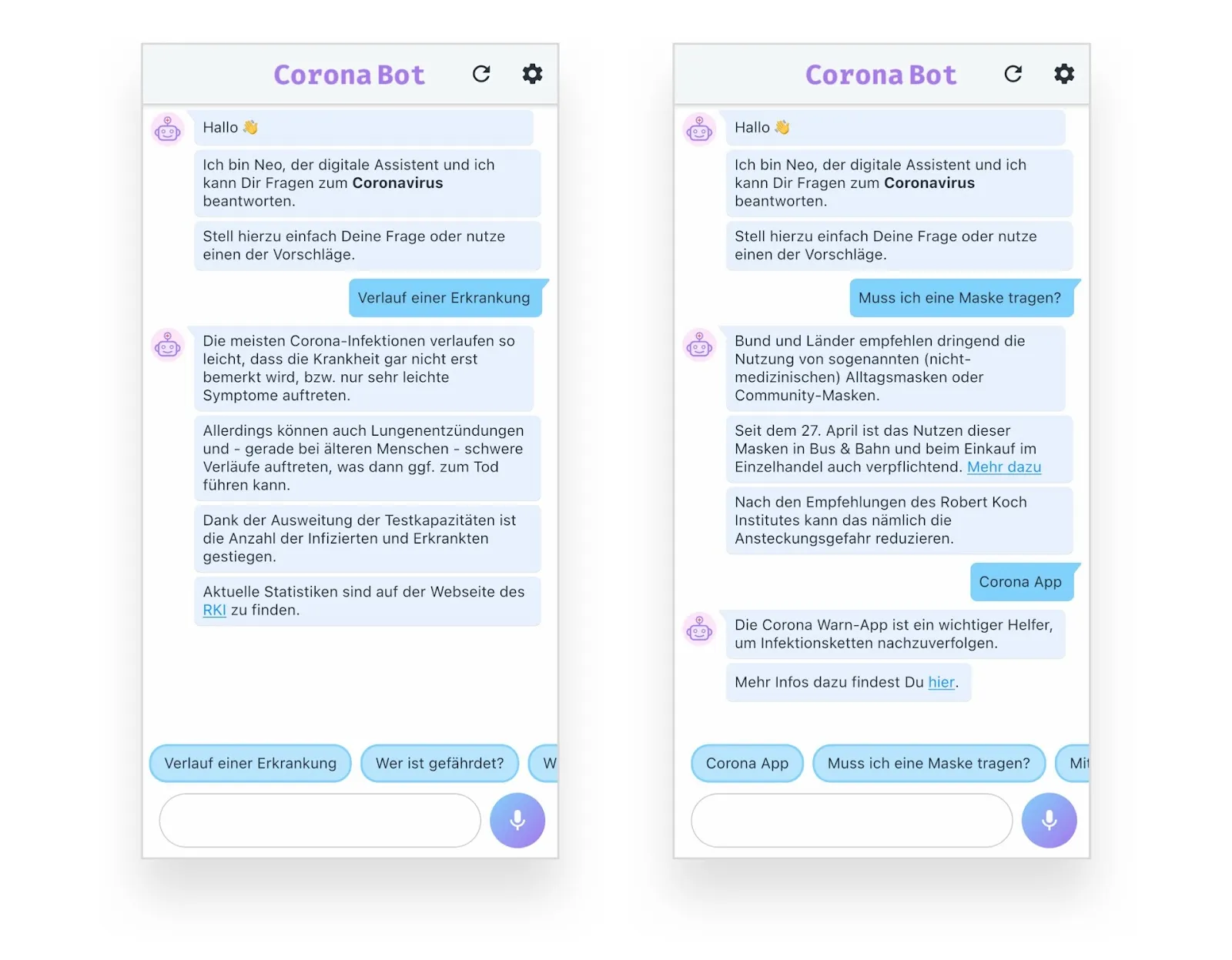
Besonders spannend wäre es hier, den Betroffenen Hilfestellung in ihrer jeweiligen Muttersprache anzubieten, um die Hürden in der Kommunikation weiter zu reduzieren. Daher ist dieser Anwendungsfall prädestiniert für das Multi2ConvAI Forschungsprojekt.
Sprachassistent zur Qualitätssicherung: Hands-free in der Qualitätskontrolle
Neben Chatbots finden digitale Assistenten auch Anwendungsfälle in Unternehmen: So sind Sprachassistenten zum Beispiel prädestiniert für den Einsatz in Qualitätskontrollen und Wartungsprozessen, da sie drei relevante Vorteile bieten: Erstens ist die Interaktion „hands-free”, sodass auch Handschuhe anbehalten werden können, die Arbeit mit den Händen verrichtet sowie gleichzeitig dokumentiert werden kann und die Arbeitssicherheit kann dadurch zusätzlich erhöht werden. Zweitens kann die Datenqualität erhöht werden, indem der Assistent die Eingaben direkt validiert und beispielsweise auf Abweichungen in Toleranzbereichen hinweist. Und drittens reduzieren Sprachassistenten durch ihre einfache Nutzbarkeit Onboarding- und Schulungszeiten, da sie intuitiv bedient werden können und in Prozessschritten auch das Stellen von Rückfragen erlauben.
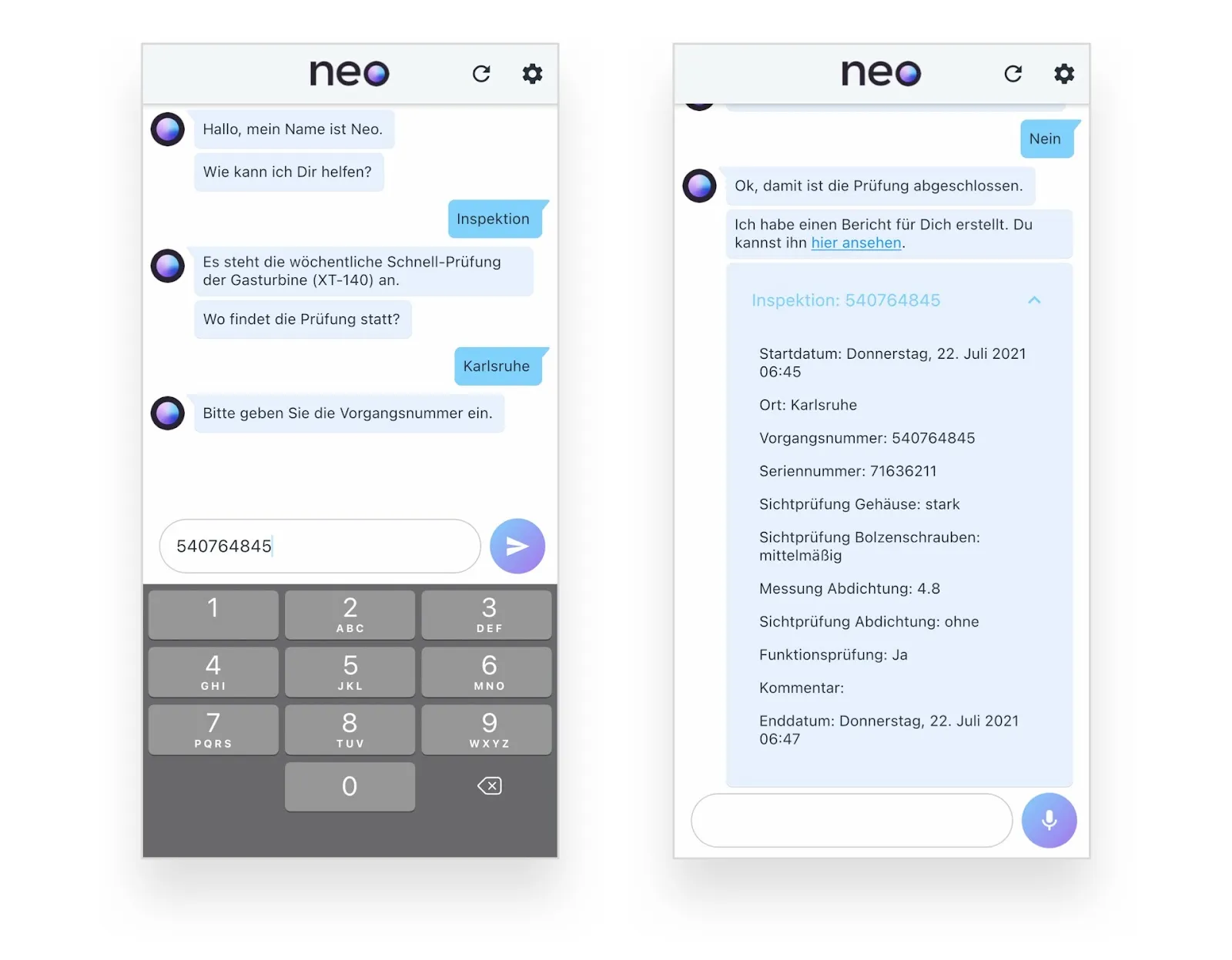
Diese Anwendungsfälle sind sehr fachspezifisch und nutzen auch Fachvokabular. Aus NLP-Sicht ist das im Kontext der Übertragbarkeit von Domänen und Sprachen eine spannende Herausforderung mit hoher Praxisrelevanz.
Last-Mile Delivery: Augen auf die Straße, Hände am Steuer und Info auf’s Ohr
Auch im Auto ist die „hands-free” Interaktion relevant. Gerade in der Paketzustellung müssen entscheidende Informationen unter Zeitdruck auf den verfügbaren Geräten gesucht werden, um bspw. zum nächsten Stopp zu navigieren oder Informationen zum Zustellprozess abzurufen. Ein Sprachassistent für die Optimierung auf der „letzten Meile” hat dabei ähnliche Effekte wie im Qualitätsmanagement: Einfache Nutzbarkeit für schnelleres Onboarding, „hands-free” (und „eyes-free”) für mehr Sicherheit und die Möglichkeit, Rückfragen zu Besonderheiten zu stellen.
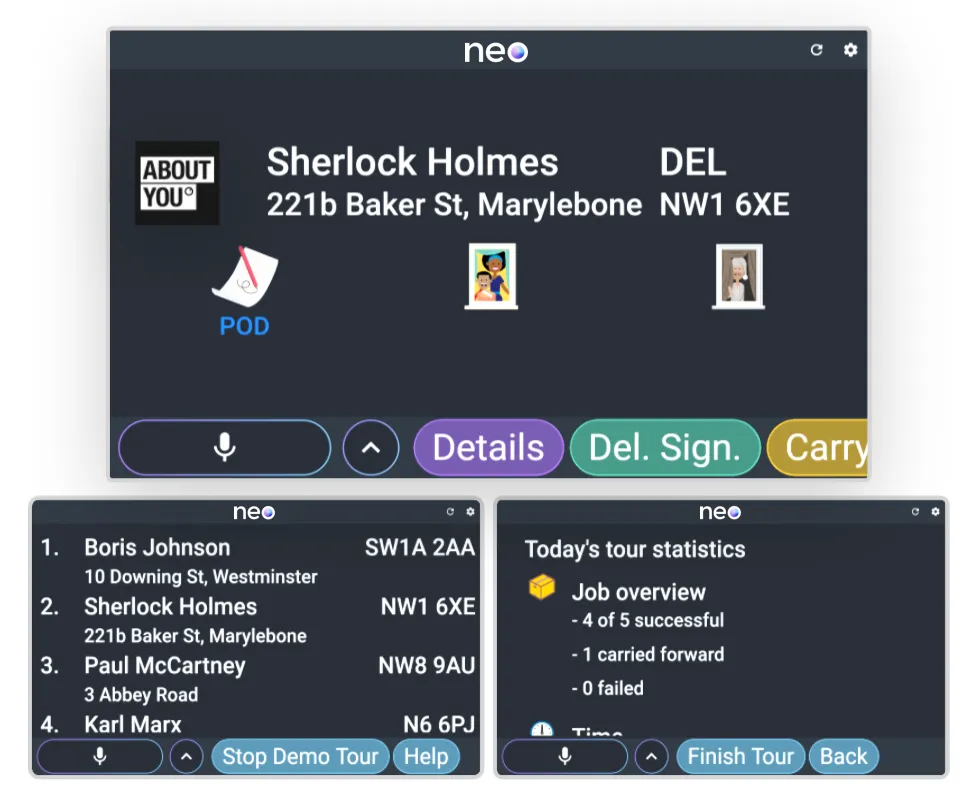
Gerade in der KEP-Industrie (Kurier-, Express- und Paket-Dienst) ist das Thema Multilingualität relevant, da diese häufig länderübergreifend arbeitet und eine diverse Belegschaft hat. Aus Sicht der Trainings- und Dialogdaten hat man hier außerdem ein interessantes Themenfeld mit komplexen Konstellationen aus Eigennamen, Straßen- und Ortsnamen sowie kurzen Befehlen mit teils domänenspezifischen Vokabular.
Ausblick
Der Transfer von Modellen und Dialogen auf andere Domänen und in andere Sprachen ist in der Praxis immer noch schwierig und mit enormem Aufwand verbunden. Gerade Fachvokabular und die redaktionelle Pflege stellen oft signifikante Aufwände dar, die eine Übersetzung oder Lokalisierung nicht rentabel machen. Das Multi2ConvAI Forschungsprojekt hofft, mit dem Forschungsvorhaben einen Beitrag dazu leisten, digitale Assistenten und Chatbots einfacher domänen- und sprachübergreifend verfügbar und nutzbar zu machen.
Über die Partner des Forschungsprojekts
Das Konsortium des Multi2ConvAI Forschungsprojekts besteht aus der Universität Mannheim und zwei KMUs mit Sitz in Karlsruhe, inovex GmbH und Neohelden GmbH. Die drei Partner teilen ihre Expertise im Rahmen des Projektes in der Hoffnung aus den entstehenden Synergien zu lernen und zu wachsen.
Kontakt
Bei Fragen und Anregungen stehen wir jederzeit unter info@multi2conv.ai zur Verfügung.