· 4 min read
Tech Talk - Wie funktioniert die Multi2ConvAI Plattform?
Einblicke in die Technologien, welche wir für die Entwicklung, das Deployment und den Betrieb der Multi2ConvAI Plattform eingesetzt haben
Dieser Blogpost stellt die Technologien hinter unserer Multi2ConvAI-Plattform vor. Die Plattform verfolgt das Ziel, Forschung und Praxis im Bereich Conversational AI näher zusammenzubringen. Zu diesem Zweck soll der Austausch von domänenspezifischen Datensätzen ermöglicht und in der Folge die Entwicklung und der Betrieb von Conversational AI-Modellen vereinfacht werden.
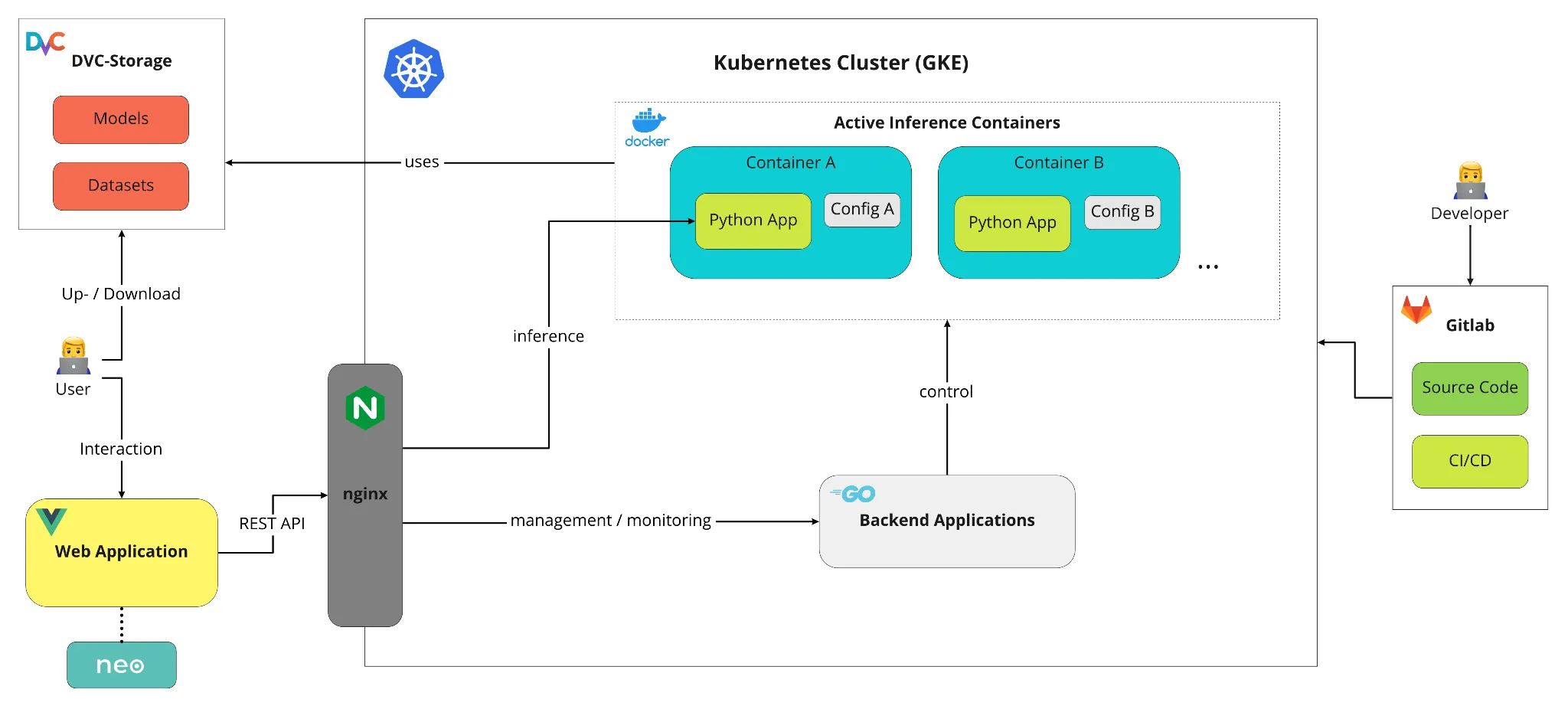
Die Darstellung gibt einen Einblick hinter die Kulissen der Multi2ConvAI-Plattform: Nutzer können über die Web Application oder die DVC-API mit der Plattform interagieren. Die Eingaben des Nutzers werden durch die verschiedenen Komponenten der Plattform propagiert und lösen die geplanten Aktionen aus. Entwickler haben darüber hinaus die Möglichkeit über Gitlab und automatisierte CI/CD-Pipelines Veränderungen vorzunehmen. Im Folgenden stellen wir die einzelnen Komponenten der Plattform vor.
Google Cloud Platform (GCP) & Google Kubernetes Engine (GKE)
Als Cloud-Ökosystem kommen in unserem Projekt verschiedene Produkte der Google Cloud Platform (GCP) zum Einsatz. Zur Orchestrierung der containerisierten Anwendungen wird beispielsweise Kubernetes in Form der GKE verwendet. Zusätzlich nutzen wir den Cloud Storage (GCS) und die Container Registry (GCR) von Google.
Web Application
Endnutzer unserer Plattform interagieren in der Regel über unsere Web Application. Hier können dann die Datensätze und Modelle verwaltet und genutzt werden. Das Frontend wird wie die übrigen Komponenten im Cluster auch als containerisierte Anwendung entwickelt. Zur Entwicklung wurden hauptsächlich die Technologien Javascript, Vue.js und inovex elements genutzt. Weitere Einblicke zu unserem Frontend gibt es in diesem Blogpost.
Inference Container
Um Modelle für den Einsatz zur Inferenz verfügbar zu machen, werden diese jeweils in einem eigenen Container deployed. Für diese Container existiert ein Container Image, welches bereits den gesamten lauffähigen Code, in Form unseres multi2convai Python Packages, enthält. Wird ein Container gestartet, so benötigt man eine Config-Datei, welche Informationen darüber enthält, welches Modell gestartet werden soll und wo die benötigten Dateien (bspw. model.bin, labels.json) gefunden werden können. Mit Hilfe dieser Informationen kann dann das Modell geladen und für die Inferenz vorbereitet werden. Jeder sogenannte Inference Container besitzt dann eine eigene, im Cluster eindeutige URL, über die man Inferenz-Aufgaben durchführen oder Metadaten abfragen kann.
Backend Applications
Damit die Inference Container nicht von Hand gestartet, gestoppt und überwacht werden müssen, haben wir Applikationen geschrieben, welche diese Aufgaben für uns übernehmen können. Sie erstellen und führen dann die jeweils benötigten Requests an die Kubernetes API aus, und bieten gleichzeitig selbst eine vereinfachte REST-Schnittstelle an, über die ein Endnutzer z.B. über unsere Frontend-App ein neues Modell deployen, laufende Inference Container überwachen oder stoppen und eine Liste aller Modelle inklusive deren URLs anfordern kann.
Data Version Control (DVC)
Für die Versionierung und Speicherung der Datensätze und Modelle wird die Python Bibliothek DVC verwendet. Damit die Inferenz Container auf die notwendigen Modell-Dateien zugreifen können, gibt es in unserem Kubernetes-Cluster ein Persistent Volume (PV), welches von den Containern gemountet werden kann, um die Daten lesen zu können. Das bedeutet, dass sich alle Modelle und Datensätze auf einem Volume im Cluster befinden und von allen Containern, die die Daten benötigen, gemountet werden. Somit liegen die benötigten Daten sehr schnell vor und es wird eine zeitliche Verzögerung durch einen Download beim Starten eines neuen Inference Containers vermieden.
Routing / Reverse Proxy (nginx)
Jeder Inferenz Container und jedes weitere Deployment im Cluster hat durch die Nutzung von Kubernetes Objekt Service eine eigene interne URL im Cluster. Der Zugriff über das Internet wird durch einen Kubernetes-Load-Balancer geregelt, welcher zunächst direkt an einen nginx Web-Server leitet. nginx dient für unser Projekt als Reverse Proxy und delegiert alle Anfragen, die an das Cluster kommen, an das jeweilige Deployment weiter. Dafür werden die internen Cluster-Services verwendet. Die Verbindung aus dem Internet zur nginx Instanz ist mit einem TLS-Zertifikat verschlüsselt, um sicheren Datenaustausch über HTTPS zu gewährleisten.
Gitlab / CI/CD
Für die Versionskontrolle aller Quellcode-Dateien wird Gitlab verwendet. Zusätzlich werden die DevOps-Features von gitlab genutzt, wodurch mit Hilfe der integrierten Pipelines Änderungen im Code zu einer Aktualisierung der deployten Applikationen in der Cloud-Plattform führen. Auch die Infrastruktur selbst kann mit Hilfe von Terraform selbst via Änderungen im Code nach dem Infrastructure-as-Code Prinzip angepasst werden.